追求有趣味的每一周-001
從此篇起,打算開一個專門的 Weekly 類別,來更加隨性地記錄每星期用過的、讀過的、想過的東西。當然,趣味並不僅僅體現在這些方面,選擇這幾種,一來是隱私暴露相對沒有其它思考方面那麼多,二來也是想要通過向特定平台「輸出」的形式來再一次加深印象。
其中有些內容向朋友們提及過,還有一些在自己的閱讀器筆記上草草記下過。但真正去一個個回溯和整理的時候才發現,當時粗糙的閱讀和隨記,其實存在很多偏差。寫這個 blog 的過程,其實也是將直覺認為有趣的東西,拿出來重新審視一番,看看是否真的如我所想。會有一些 turned out to be boring 的情況,當然發現無聊的過程是由期待接觸有趣事物的初衷所驅使的,僅僅看待過程其實也是有趣的,因此這一部分也仍然保留在了這份記錄裏。
不清楚這份周記能夠堅持多久,想起來之前在朋友推薦下開始寫的「感恩日記」,每天用簡短的話語記下讓自己想要感謝的事情,不知不覺已經堅持一個多月了。也許保持一種恆常的習慣對我來說並非難事。但其實是否堅持也沒有那麼重要,在寫的每一點,都是投入在有趣事物中的證明,這就足夠了。
用發掘生活的樂趣,來抵抗大環境的荒誕。
有趣工具
BeatPrints - 卡片形式分享 Spotify 音樂
工具地址:BeatPrints ✨

卡片審美確實怪好看的,加入和專輯封面匹配的顏色條是我非常喜歡的設計。
安裝過程中選擇儲存的路徑這一步有些 tricky,不清楚是不支持含中文的目錄還是不支持雲存儲,想存入個人 Ondrive 的時候會報錯,於是作罷,還是存入本地路徑中。安裝完以後直接在終端輸入 beatprints 會打印一個酷酷的 logo:
後面就按照提示語句選擇即可。
音樂碼的掃描也 test 過,能夠直接跳轉 Spotify 播放,倒是不錯。
兩個比較大的缺點:
- 可能由於卡片本身的長寬是定死的,選擇歌詞的上限只有四句話,甚至比 Spotify 分享到 Instagram 的卡片還少一句,有的時候會導致不得不截斷意義連貫的歌詞,這一點不知道以後開發中會否改變;
- 每一次運行都需要一條條命令行選擇過去,而且必須在工具內進行再次檢索,效率還挺低,如果能直接在聽歌的時候分享鏈接、直接讀取生成卡片就好了。
TheBoringNotch - 把 Mac 瀏海變成新的靈動島
工具地址:TheBoringNotch ✨
雖然手機還沒用上靈動島,但可以在電腦上先體驗一下,讓瀏海變得沒那麼無聊。
很喜歡每次停留在瀏海上的時候,觸控板給到的觸覺反饋,交互體驗很棒。
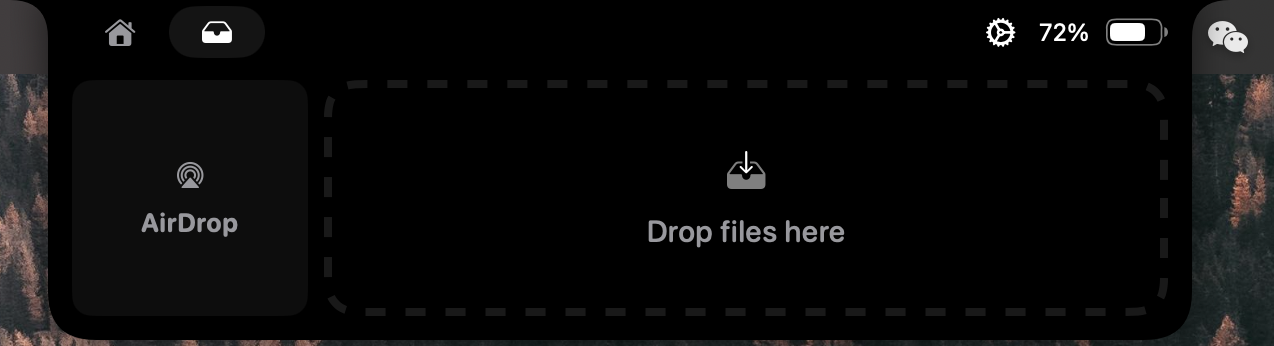
拖拽進行 airdrop 的功能很方便:
不過在我最關注的音樂播放器功能上,目前並不能同步專輯封面和進度條,點擊 ▶️ 時確實能夠播放,但其它功能都沒有辦法實現:
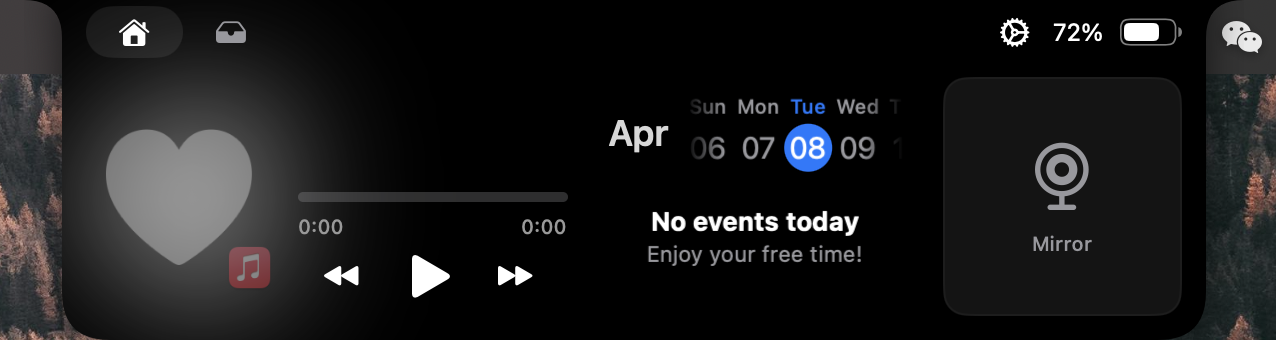
翻了翻 GitHub issues,發現是 macOS 15.4 共通的問題,目前尚未被解決:
https://github.com/TheBoredTeam/boring.notch/issues/417
因為要兼顧到工作主機和遊戲主機的 win 系統,所以一直使用 Outlook calendar,但目前這款工具只能同步顯示 Apple calendar,對我而言還是不太方便。
兩方面問題,可以再等一段時間,看看開發進度如何再用。
Pearcleaner - 自動卸載應用程序的殘留文件
工具地址:Pearcleaner ✨
很輕量化的實用工具,小而美!正好卸載上一個軟件時,自動跳出來清理了文件🧹,極簡的使用方式,沒有學習成本。
Ice - 折疊菜單圖標
之前試用過 macbartender,但是因為 App 圖標太醜而沒有繼續用(?),Ice 的 logo 倒是很好看,UI 也比 Bartender 更好看一些(雖然知道並不會經常打開它)。
通過 Ice - Github 的 release 下載下來,就可以免費使用了,3.34 MB 歌頌小而美!
感覺開發者很有趣,在縮略圖標的選擇上出現了🕶️:
把最經常用的幾個 pin 在顯示圖表上,其餘的都隱藏了起來。當前的顯示長度也是視覺上非常舒服的,基本上和大多數打開的 app 在左側的工具欄長度相當。設置中,選擇了 hoover 顯示所以也不用多按一下。

調酒筆記 - 想喝酒的時候隨機學點經典的
工具地址:調酒筆記 ✨
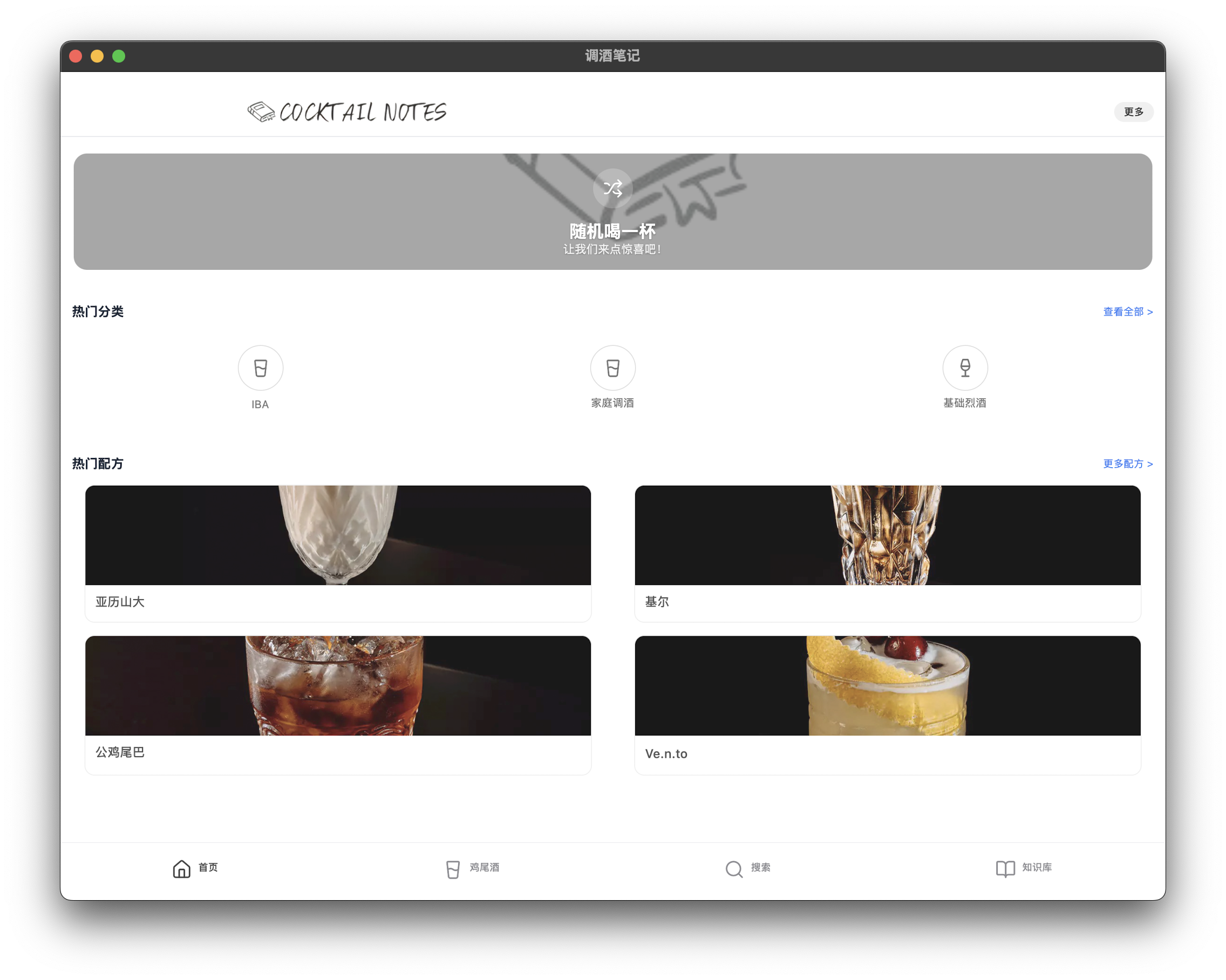
經過長達七個月的「喝酒不應期」,最近終於沒有再感覺到代謝物乙醛在呼吸中積聚的難聞味道了,意味著又可以重拾調酒大業了(bushi)。研一入學後的第一個生日,收到的禮物裏有很齊全的調酒設備,但大多數時候其實還是懶到應用一些便利店調酒法——唯一區別就是用的基酒品質更好、更多樣。
上一次自研出來最喜歡的雞尾酒配方是諾迪斯金酒、金橙利口、鮮榨檸檬汁、蘇打水和迷迭香的組合:

這款酒還在當年的課題組年夜飯上現製給大家喝了兩輪。但至今還未獲得命名。
至於更為經典的調酒配方,基本上從來沒仔細鑽研過,調得隨性,碰上好喝的就記下,不好喝的就忘記。但也許這個 app 能帶給我一些學習的新鮮感,也更容易在店內點到不那麼難喝的酒(畢竟試錯成本太高)。
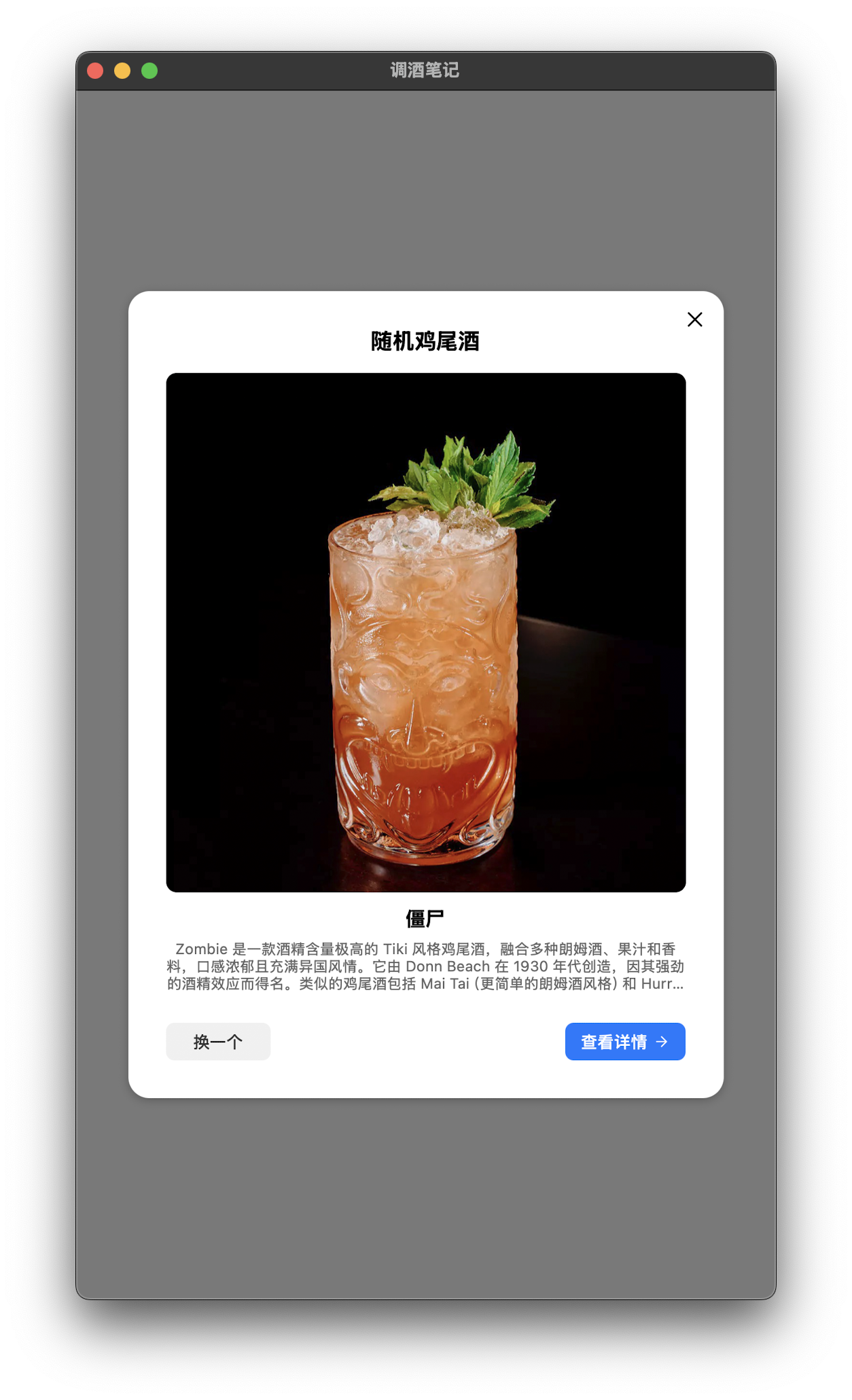
還挺喜歡隨機喝一杯的設計,恰好搖出了在店裏最最最喜歡喝的殭屍。不知道是否有心情去買下那麼多不同的朗姆呢~
有趣網站
How to be a Programmer
Introduction · How to be a Programmer ✨
讀研以後寫 R 寫得太太太太太多了,但它畢竟是一種統計工具而不是真正的代碼語言,寫多了以後感覺代碼能力顯著下降。在編寫第一個面向用戶的工具,而不是自己用著舒服的 pipeline 時,明確地體會到了有心無力的感覺。很多的考量涉及到對環境和數據結構的理解,任何一小點的優化都伴隨著大量的修改,而這些在平常分析數據時幾乎不會接觸到。
現在有了 AI 幫手,學一個新的語法、找一些 bugs、解讀他人的代碼等等,幾乎無需動腦只需要張口問就行了。但這樣做的後果是,人變得越來越沒有耐性,而腦子不用是會生鏽的(確信)。
將 AI 當作工具來用,要掌握到哪個度才是合適的——最近一直在思考這個問題。在代碼編寫中,人腦的巧思在什麼地方發著不可替代的光?
看這個網站的時候看到了一點點指引:
调试技术中分治的关键和算法设计里的分治是一样的。你只要从中间开始划分,就不用划分太多次,并且能快速地调试。但问题的中点在哪里?这就是真正需要创造力和经验的地方了。
忽然對這個問題有了一點想法。之前用 AI 生成的代碼,哪怕再詳盡地描述需求,也很少能夠直接跑通。而出現問題的地方,通常都是一些在我找出以後會眼前一黑地感慨“究竟是為什麼會寫出這種鬼邏輯”的東西,這是 de 自己的 bug 和 de AI 的 bug 最不同的地方。如果沒有耐著性子去找問題,而直接給出 error 信息要求 AI 自行調適它的代碼,幾乎從來都行不通。而全程自己寫代碼的過程中,什麼時候要加入檢查點、什麼時候直接往後寫就行,都在經驗積累的背景下不斷給予自己反饋。
網站後面寫道:
需要输出的日志数量总是一个简约与信息量的权衡。太多的信息会使得日志变得昂贵,并且造成滚动目盲,使得发现你想要的信息变得很困难。但信息太少的话,日志可能不包含你需要的信息。出于这个原因,让日志的输出可配置是非常有用的。
這一點也讓我重新思考了我開發的小工具的日誌。在使用 AI 檢查時,AI幾乎不會在簡約與信息量之間進行權衡,它會想盡辦法輸出盡可能多的信息。這對機器而言似乎是好的,它們讀取信息的速度遠遠超過人腦,所以盡可能輸出多的信息有助於判別問題所在。但是這直接降低了日誌本身可讀性和可用性,對於用戶而非開發者而言,這樣的繁雜日誌可能根本就無法指示解決問題的方向。
剩餘內容還需要慢慢看。有一些可能對於當前的我而言用不上(畢竟我不是真的程序員),但讀到一些有啟發性的東西感覺還是挺不錯的。
MyRetroTVs - 看不同年代的電視節目
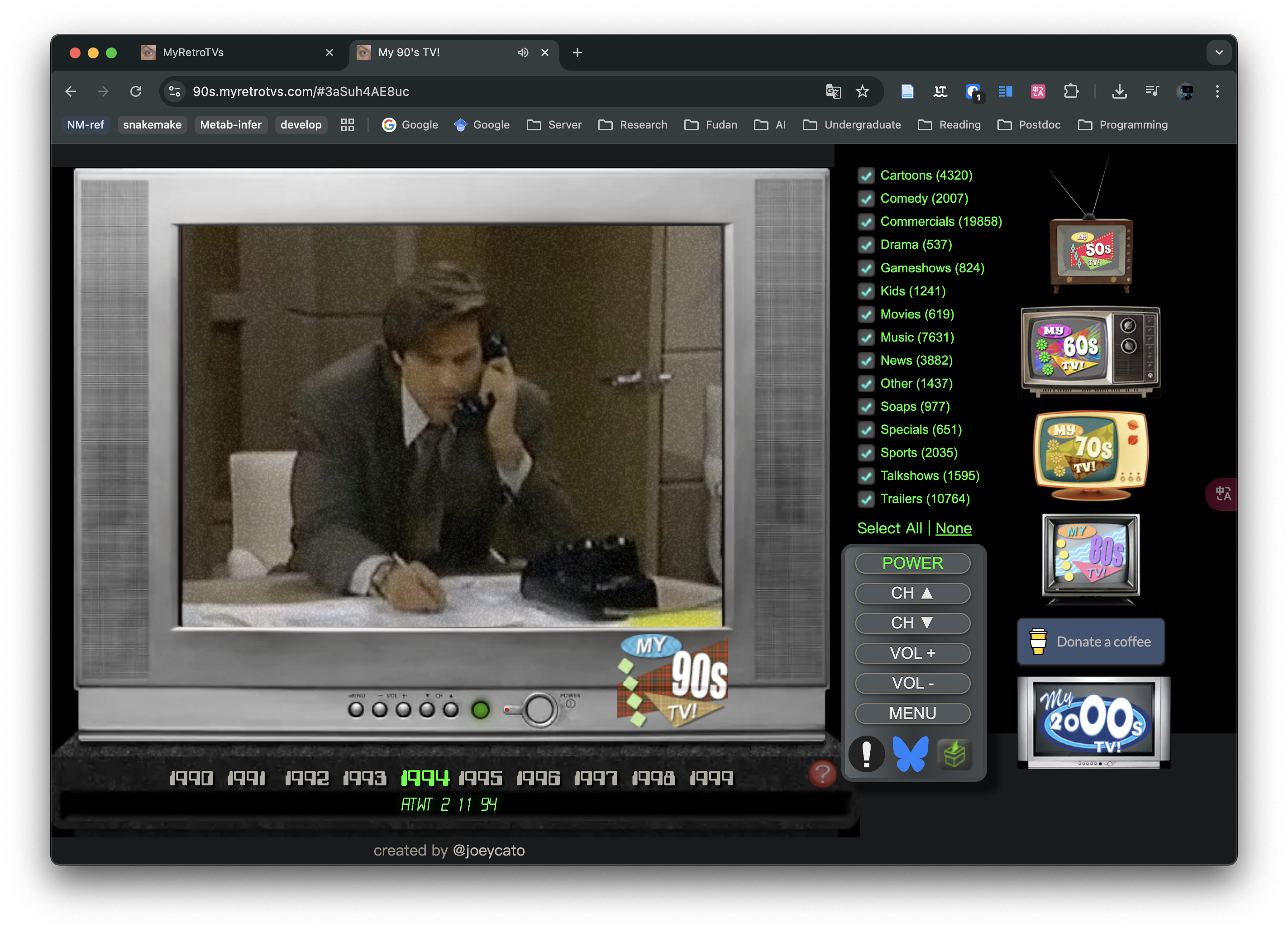
太酷了⋯⋯可以看不同年代的電視📺復古愛好者狂喜。九十年代的音樂真好聽啊,不得不說。
有趣論文
微生物組測序偏差的評估和矯正
Consistent and correctable bias in metagenomic sequencing experiments
目前使用過 16S 和普通的 RNA-seq 來定量微生物組成分,但基本沒有考慮過可能的定量誤差。
這篇提出的矯正方法本質上還是挺簡單易懂的,但作者提供的 R 包,其實並不能直接 apply 到常規的測序流程中(無法獲得所謂的「實際豐度」)。需要在設計實驗的初期就將均勻混合微生物的樣本和其它實驗樣本一起建庫測序,以達到對實驗過程中產生的誤差進行控制的目的。這一點其實就跟用於測量環境/污染微生物的陰性對照樣本一樣難以獲取,畢竟我們總是依賴於別人“施捨”給我們樣本(?)。但是這樣一種處理思路是可以借鑑的,如果未來有機會自己從頭設計和主導實驗項目的話。
微生物組的批次效應矯正方法 DEBIAS-M
和前一篇不同,這個方法主要關注的是不同測序批次之間的偏差。之前導師提到過想要對公共數據進行整合,來探究微生物組信息。不同的測序流程和平台,會使得數據集之間的偏差變得更加難以控制。可能可以用到這個方法,雖然其實不是很想做這一來 pan-cancer 的整合分析。
活細菌還是死細菌?
Recycling dead bacteria to fuel macrophage immunometabolism
Macrophages recycle phagocytosed bacteria to fuel immunometabolic responses
非常有意思的一篇,探討了體內微生物的生境。雖然是從巨噬細胞進行能量利用的角度去做的比較,但誰知道腫瘤細胞是否也會有這樣的利用呢?過去大部分瘤內菌的研究,包括我參與的那篇,其實都 assume 細菌是具有活性的,因此才會有代謝上的競爭拮抗或彼此促進的可能。但是體內是否真的是這樣一種共生關係,單單從靜態的電鏡照片上,其實並不能說明情況。也有研究者給出動態的信息:Susan Bullman 之前有做過類器官上的活菌視頻,但是類器官本身只是實驗室環境構建的,活菌的引入也是一種人為干預;蔡尚實驗室之前做了細菌侵染腫瘤細胞的實驗,但也是基於細菌本身活性的 assumption,然後在實驗上引入活菌,而不是在體內真正觀察到了活菌生境。是否存在一種,腫瘤細胞利用死菌給自己提供養分,就如巨噬細胞那樣呢?還是很值得深思。
另外也有幾點值得思考:
巨噬細胞抗菌過程中,反而是抗炎 + 抗 ROS 的,是否可以改變 TME?
Macrophages tailor their anti-bacterial response by promoting an anti-inflammatory state via glutathione and itaconate, which in turn decreases production of reactive oxygen species (ROS) and IL-1β.
代謝與細胞內通路之間的關係上,文章提到巨噬細胞利用死細菌是由其釋放的 cAMP -> AMPK 對 mTORC1 的抑制所介導,而這一過程還能抑制糖酵解。如果相似的過程能夠發生在腫瘤細胞中,聯繫 warburg effect 的話,利用死細菌干預腫瘤可能有很強的抗癌效力?
令人懷疑的 beta coefficient
一篇腸道菌對體重影響的研究文章,在最開始分析代謝物的時候,使用了 beta coefficient 來尋找對體重有正/負面貢獻的潛在代謝物。
讀到的時候,覺得 beta coefficient 是個很陌生的詞,還想著“這是什麼新方法我來學”。查了查發現,喔原來就是線性回歸模型裏 Y = βΧ + ε 的那個 beta 啊⋯⋯有被自己蠢到。
但是作者做的是隊列中的觀察性研究,混雜因素很難得到控制(文章中只控制了性別);代謝物之間也肯定不會是獨立關係;散點圖看上去也不算很線性。即使如此,還是發了 Nature Metabolism 唉。也許是先做出了實驗,然後再做一下數據的分析來服務于已有實驗結果吧。
神經-腫瘤 crosstalk 之巨噬細胞的促神經生長作用
Macrophages promote nerve growth in both tumours and spinal cord
一年多以前跟導師提及讓我感興趣的研究方向,最近幾個月似乎變得越來越火了,但很可惜因為一些客觀原因被否決了導致沒有辦法真的參與到相關研究中去。
這篇的思路很神奇,並不是我過去讀到的那些研究神經生長對腫瘤的支持作用或者腫瘤本身借助免疫系統和神經系統進行交互,而是將腫瘤微環境中的 TAM (tumour-associated microphages) 視為一種工具性的細胞,給脊髓損傷後再生提供支持。很有意思的一種跨領域研究方式。
原文目前還在預印本上:
Tumor-associated macrophages enhance tumor innervation and spinal cord repair
期待一下會有什麼樣的同行評議以及會發到什麼地方。
腫瘤微環境之用 NicheCompass 分析空間組學來揭示生態位
Quantitative characterization of cell niches in spatially resolved omics data
還沒真的實操過空轉數據,但是到處看方法(?)。之前聽的講座也非常關注 neighbourhood 的信息,這篇的方法也是。
給出了不同 seeds 和不同鄰域圖的訓練,能夠表現穩健還是挺好的(用過太多稍微調整一下參數就變了很多的方法,真是不知道該怎麼相信這樣的結果)。
不過單從文章提供的圖上看,他們的測試數據是真正單細胞意義上的空間組(我們未來可能也測不起),而不是我們更容易接觸到的 spots 類型,不知道會否有影響。
總之先存檔一下備用。
信號依賴的增強子激活過程中的eRNA檢查點
An eRNA transcription checkpoint for diverse signal-dependent enhancer activation programs
看了這篇以後,越發覺得過去接觸到的 eRNA 相關泛癌關聯分析相形見絀。想要真的探究一個並不那麼好抓取的物質,在細胞內的存在和作用,應該盡可能地去提升數據來源的可靠性,而不是放寬「抓取」本身的範圍去容納更多的假陽性只為了得到一個看起來 significant 結果。
一些知識亂鏈:ATAC / CUT & Tag 標準化方法可能可以藉鑒。
ProtGPS 預測蛋白質的細胞內位置(含 condensate compartments)
Protein codes promote selective subcellular compartmentalization
之前聽講座看到的大多數預測蛋白質胞內定位的方法,都不含各類 condensate compartments(也可能是我孤陋寡聞,不是很熟悉的領域)。這篇能夠預測的各種類型看起來非常全面。合作組是專攻 nuclear speckles 的,師妹也掛靠那邊在做與之相關的研究,但目前陷入瓶頸。不知道能不能給她提供一些方法上的便利。
其它思考
Cell type percentage 存在的 bias
最近草草看了一些單細胞的文章,感覺 cell type percentage 為核心的做法實在是非常“風靡”。但是在取樣過程中,percentage 本來就很容易因為樣本位置、操作手段產生改變,根本就很難用這個值去代表樣本的真實情況。但是幾乎所有人都在用這樣的方法,為什麼呢?
想起來去年聽到最 impressive 講座,Joseph Costello 講的,他們看起來有足夠的資金,但並不迷信單細胞水平的做法,而是多點取樣進行傳統的 bulk 測序,去識別不同的表達模式,然後重構腫瘤的空間狀態。感覺這樣的手段,其實比看起來 fancier 單細胞更容易避免那些取樣和實驗帶來的偏差,並不隨大流地去追隨如日中天的技術才能真的服務于研究目的。(雖然後面講到的一些腫瘤純度相關以及三位基因組的內容,沒太聽明白。)
開合作組組會的時候,合作導師最近常提,要加入更時新的技術才能滿足審稿人的胃口。有些技術的更新換代確實帶來的很多好處,但是對應的常規分析方法是否從原理上/本質上說明了我們要探究的問題,還是很值得質疑,不能因為大家都說某個方法說明了某種問題就是對的。
很相似的一點,是看到一篇文章講述使用 PCA 觀察樣本分組情況
復現與復用他人研究中的代碼
上週讀了一篇採取了非常規方式分析空間轉錄組數據的文章,單從文章本身的思路來看,這種非常規方法似乎沒有什麼問題,有些地方也會比常規流程看上去更加客觀。這對只讀了文章的我而言有一些分析思路上的啟發,於是我將其分享給了從事同種癌症研究、正在做空轉的同門。但是當同門嘗試用作者發布的數據和代碼復現結果的時候,發現了各式各樣令人困惑的點。最初我對文章本身的印象,在他發現的各種問題中逐漸被瓦解。
我需要更多地提醒自己——寫論文並不真的總是客觀描述,真正能揭示方法實現過程的是無法通過自然語言加以修飾的代碼。
過去我復用他人代碼基本上僅限於利用開源工具時,而沒有在各種組學的分析流程上去仔細研究過哪篇文章的代碼。這件事也許給了我一個啟示,當我感覺到一篇文章的分析很好時,還需要去看看它是否真的有文章中寫得那麼好,是否有 tricky 內容並沒有被囊擴在文章的講述之中。